
So this post hasn’t aged well. I would highly recommend NOT using OpsWorks for deployments
So the best place to start is with the example setup:
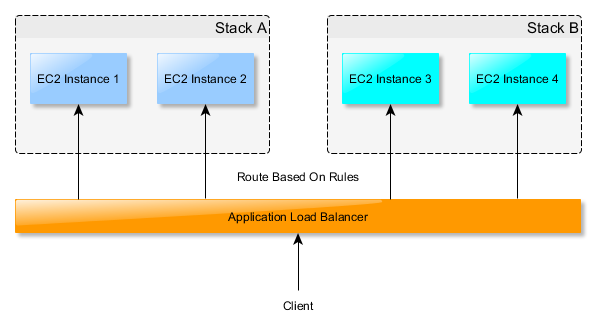
Pretty simple right? Application Load Balancer distributes the requests to the instanced based on rules. This is where everyone should be able to get to pretty easily. So, how do we take this to the next level and add AutoScaling? Let’s walk through it step by step:
1. Auto-add new instances to Target Group
You can follow this tutorial but there are a couple gotchas (though realistically, this was one of the easier parts): https://aws.amazon.com/blogs/mt/use-application-load-balancers-with-your-aws-opsworks-chef-12-stacks/
One gotcha is that for some reason, the code out of the box doesn’t work. The error I got was
ruby Seahorse::Client::NetworkingError: SSL_connect returned=1 errno=0 state=SSLv3 read server certificate B: certificate verify failed
After a quick google search, found that you need to use the AWS bundled cert and you can do that by adding:
Aws.use_bundled_cert!
Under
require "aws-sdk-core"
The other “gotchas” are just following the directions. Make sure that the role has permissions and the custom json for the stack has the settings for the target group arn.
We’re ready for auto-scaling now right? Nope. If you go to (within OpsWorks and the stack you want to set to autoscale) “Instances” -> “Load-based”, flip “Scaling configuration” to “On”, you’ll see that you need cloudwatch alarms to get it to trigger a new instance setup and to take ones down.
2. Setup Auto Scaling Groups in EC2
The autoscaling groups are responsible for monitoring the machines in the cluster. It’s the only way (I’ve found) to get aggregated metrics (alarms) on a group of windows machines.
Things to keep in mind when you are creating Launch Configurations and Auto Scaling Groups:
- You don’t need Cloudwatch monitoring on the groups (if you don’t want, it costs extra money)
- Don’t fret about instance sizes, group sizes, etc. This is all actually going to be managed by OpsWorks
- When creating the Auto Scaling Group, in step 1, make sure to go to “Advanced Details”, check “Load Balancing” and set the Target Group this associates with
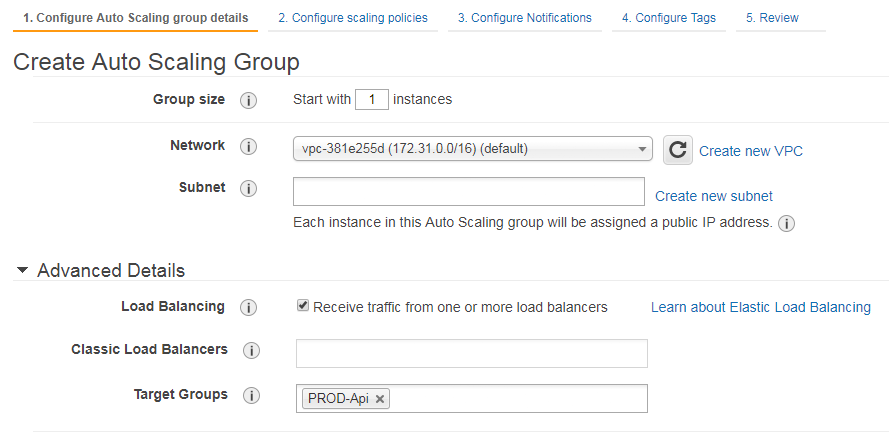
- Make sure to select all the Subnets you’ll need. If you don’t have a Subnet of a specific instance in OpsWorks, it’ll fail to setup the load-bases Instance
- Don’t configure Scaling Policies. The defaults are terrible, especially with Windows
3. Setup Custom Cloudwatch Alarms for Auto Scaling Group
Now that there’s an auto scaling group, we can monitor across it. We’ll need 2 alarms, 1 for when we want to spin up new Instances, and 1 for when we’re ready to shutdown load-based Instances.
Here’s the configuration that has worked for me so far:
- UP Alarm:
- Threshold: CPUUtilization >= 75 for 5 minutes (or 1 consecutive period)
- Statistic: Maximum
- Treat missing data as: ignore
- Period (5 minutes
This makes it so that if, across the auto-scaling group, if over a 5 minute period of time it hits 75%, then we’ll auto-provision and setup another instance. This is a pretty aggressive alarm so you may want to adjust for your system, but with how long it takes for Windows Instances to setup, we opted for aggressiveness over being “sure” that it is needed.
- DOWN Alarm:
- Threshold: CPUUtilization <= 50 for 15 minutes (or 3 consecutive periods)
- Statistic: Maximum
- Treat missing data as: ignore
- Period (5 minutes)
This is also a rather aggressive down alarm. The Instances in the auto-scale group needs to not have a max of 50% for over 15 minutes for the load instance/s to shutdown. Once again, this was based off of what our usage looks like, so tweak away for your use case.
4. Hooking it all up – OpsWorks
Back in OpsWorks, go to the stack you want to setup AutoScaling on and in the left menu navigate to the “Load-based” Instances.
Set “Scaling configuration” to “On”, and select the alarm you just created for high CPU usage for the UP alarm, and the alarm you just created for low CPU usage for the DOWN alarm.
Below, you should see +Instance button. Here is where you add instances that will be kept on the side for autoscaling.
Some extra points:
- I avoid pictures of the AWS interface because 1, it’s awful, and 2, it changes frequently enough where understanding the ideas behind it is more powerful than copy pasting what’s in pictures
- The only reason for the Auto Scaling Groups is monitoring. You need 1 alarm for the UP and DOWN actions, and otherwise it doesn’t seem possible to get aggregate metrics on Windows machines. I haven’t done it yet, but added points if you can (as part of the CHEF setup/shutdown) add the load-based Instance to the Auto Scaling Group, probably via the AWS API. This way the new Instance affects the next UP and DOWN alarms. Theoretically if the load balancer is doing its job, it’s unnecessary, but no load balancer is perfect.