

Recently Redis timeouts began time pile up and it took a while to figure out how to scale to make things more available. With a 5 second timeout, timeouts were pretty catastrophic considering there were clients relying on a sub 4 second call time.
Issues Fixed in Process
- GET calls not using replica
- Downtime-less Redis Scaling
- Only 1 of the X replicas per shard getting cache hits
The original setup
We don’t have much cached data (about 70mb), we just wanted access to it quickly and offload the calls from our SQL database, so micros worked well for us. It was a starting point.
I followed the basic usage instructions for setting up StackExchange.Redis:
https://stackexchange.github.io/StackExchange.Redis/Basics.html
using StackExchange.Redis;
...
ConnectionMultiplexer redis = ConnectionMultiplexer.Connect("localhost");
// ^^^ store and re-use this!!!So we stored it in a static variable and made it a singleton:
public static class RedisConnection
{
public static IDatabase GetDb(int id)
{
return ConnectionMultiplexer.GetDatabase(id);
}
public static void Connect(string connections)
{
if (ConnectionMultiplexer != null && ConnectionMultiplexer.IsConnected)
{
return;
}
ConnectionMultiplexer = StackExchange.Redis.ConnectionMultiplexer.Connect(connections);
}
public static void Connect(ConfigurationOptions configuration)
{
if (ConnectionMultiplexer != null && ConnectionMultiplexer.IsConnected)
{
return;
}
ConnectionMultiplexer = StackExchange.Redis.ConnectionMultiplexer.Connect(configuration);
}
private static IConnectionMultiplexer ConnectionMultiplexer { get; set; }
}NOTE: DO NOT USE THIS, IT IS NOT CORRECT AS WE WILL TALK ABOUT LATER
Issue #1 – GET calls not using replica
So it was setup in the config to have both the master and replica endpoints as hosts and an assumption was made Redis or the client would be smart enough to balance the load to the replicas. That was an incorrect assumption.
So, naively, our calls to get data from Redis looked like:
db.StringGet(key);Ran some tests and lo and behold, all requests ran only through the master. After some digging found that command flags can be used to prefer the replica (or slave) for read only calls. It’s as easy as changing that code to:
db.StringGet(key, CommandFlags.PreferSlave);Issue fixed! We were balancing load between the master and the replica. Good enough for now.
Signs of trouble
As the company grew, timeouts became more common, and at a 5 second timeout, that kind of delay is unacceptable. The company signed a large client who accessed our APIs directly and were relying on a sub 4 second response. Along that path there were calls that hit Redis and the request to redis would timeout at 5 seconds from time to time. Time to scale up.
Issue #2 – Downtime-less Redis Scaling
Seeing the writing on the wall with the issue with the current cluster, some research was done on what’s the best way to scale our caching layer. We don’t have a lot of data, but we want access to it very very quickly.
What was landed on was Redis Cluster. ElastiCache has a very good managed version that, once set up properly, handles downtime-less deployments. As long as you have a single replica, it can scale without downtime. Not much more to say here. Good job Amazon!
The Sort of Naive Cluster Setup
Originally the thought was, scale up to larger machines. Keeps the cluster simple and increases speed.
The issue is though, there isn’t a lot of data. And the only difference between a t3.micro and an r5.large is the amount of memory it has. They have the same CPU/s and per Redis documentation:
Redis is, mostly, a single-threaded server from the POV of commands execution (actually modern versions of Redis use threads for different things). It is not designed to benefit from multiple CPU cores. People are supposed to launch several Redis instances to scale out on several cores if needed. It is not really fair to compare one single Redis instance to a multi-threaded data store.
https://redis.io/topics/benchmarks
Not to mention trying to scale r5.large instances horizontally gets expensive FAST.
So the decision was made to scale up to t3.small and do 2 shards w/ 2 replicas each for a total of 6 servers (don’t forget about the 2 master nodes).
It was launched, and boy did it not run very well. Looking at the metrics revealed that only a single replica for each shard was getting hit.
Issue #3 – Only 1 of the X replicas per shard getting cache hits
So to really scale, making sure that we can use multiple replicas at the same time seemed like an important thing. No one wants to pay for servers to just have them sit there.
After some digging, a github issue was stumbled upon that raised the idea of a connection pooler.
Sometime when we have high throughput we get redis timeout because we only have one tcp connection and qs in it grows bigger and bigger after a while. [Redis] suggest to use a pool of ConnectionMultiplexer objects in your client, and choose the “least loaded” ConnectionMultiplexer when sending a new request. This should prevent a single timeout from causing other requests to also timeout.
https://github.com/imperugo/StackExchange.Redis.Extensions/issues/160
This is exactly what we were seeing! Seems insane that this recommendation wasn’t found anywhere else but this issue, and luckily, they had added a connection pooler to their StackExchange.Redis.Extensions library.
With that, StackExchange.Redis.Extensions.Core was added and our connection management changed to the following (kind of, had to leave in the old code to not make a breaking change but the idea is correct):
public static class RedisConnection
{
public static IDatabase GetDb(int id)
{
if (ConnectionPoolManager != null)
{
return ConnectionPoolManager.GetConnection().GetDatabase(id);
}
throw new Exception("ConnectionPoolManager has not been initialized");
}
public static void InitializePooler(RedisConfiguration configuration)
{
if (ConnectionPoolManager == null)
{
ConnectionPoolManager = new RedisCacheConnectionPoolManager(configuration);
}
}
private static RedisCacheConnectionPoolManager ConnectionPoolManager { get; set; }
}Now whenever a new cache request is being made, it will use the least used ConnectionMultiplexer!
Looking at the source code of the RedisCacheConnectionPoolManager helps clear up how it works:
Based on the configuration passed it, it will create a Lazy ConnectionMultiplexer til the count is equal to the configuration’s pool size. Then when a connection is retrieved, it will either get a non-initialized connection multiplexer or it will return the multiplexer with the fewest requests in the queue.
So a common sequence could go as follows:
- GET 1 comes in and queues on Multiplexer 1 to go to Replica 1
- GET 2 comes in and queues on Multiplexer 2 to go to Replica 2
- GET 3 comes in and queues on Multiplexer 3 to go to Replica 1
- GET 2 completes
- GET 4 comes in a queues on Multiplexer 2 to go to Replica 2
Since Replica 2 is working faster than Replica 1, its queue is allowed to process faster without Replica 1 holding up the entire process in this server. To be honest, I’m not sure if it’s in the client or ElastiCache or Redis Cluster that decides what node a call gets delivered to, but with the Connection Pool it gives the proper behavior and that’s what was the goal.
Summary
For the love of God, please use a Connection Pool with Redis unless you are running a highly horizontally scaled application layer or have a small, non clustered server. Going forward though, I personally will only use Redis Cluster with a Connection Pool in the clients.
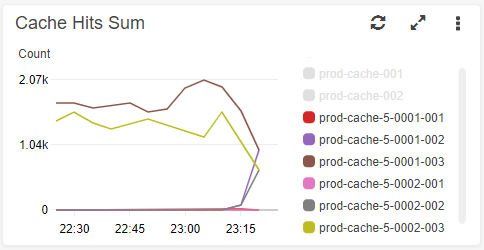
The setup is still 2 shards with 2 replicas for each shard (6 nodes) and I’m honestly not sure if the shards are worth it or if it’d be better to do something like 1 shard with 5 replicas since the data-set is so small, but for now there’s other more important things to work on now that caching is stable.
If you have advice, corrections, or comments, please leave a comment below!